A feeling of complete absorption when you’re engaged in something you love to do without being disrupted by anxiety or boredom.

References
- Flow (psychology), https://en.wikipedia.org/wiki/Flow_(psychology)
A feeling of complete absorption when you’re engaged in something you love to do without being disrupted by anxiety or boredom.
Mamungkukumpurangkuntjunya Hill, is a hill in South Australia. The name means “where the devil urinates” in the regional Pitjantjatjara language. The name is the longest official place name in Australia. The hill is located approximately 108.8 km west north-west of Marla.
A look at historical house prices in Sydney and Melbourne from 1880 to 2010.
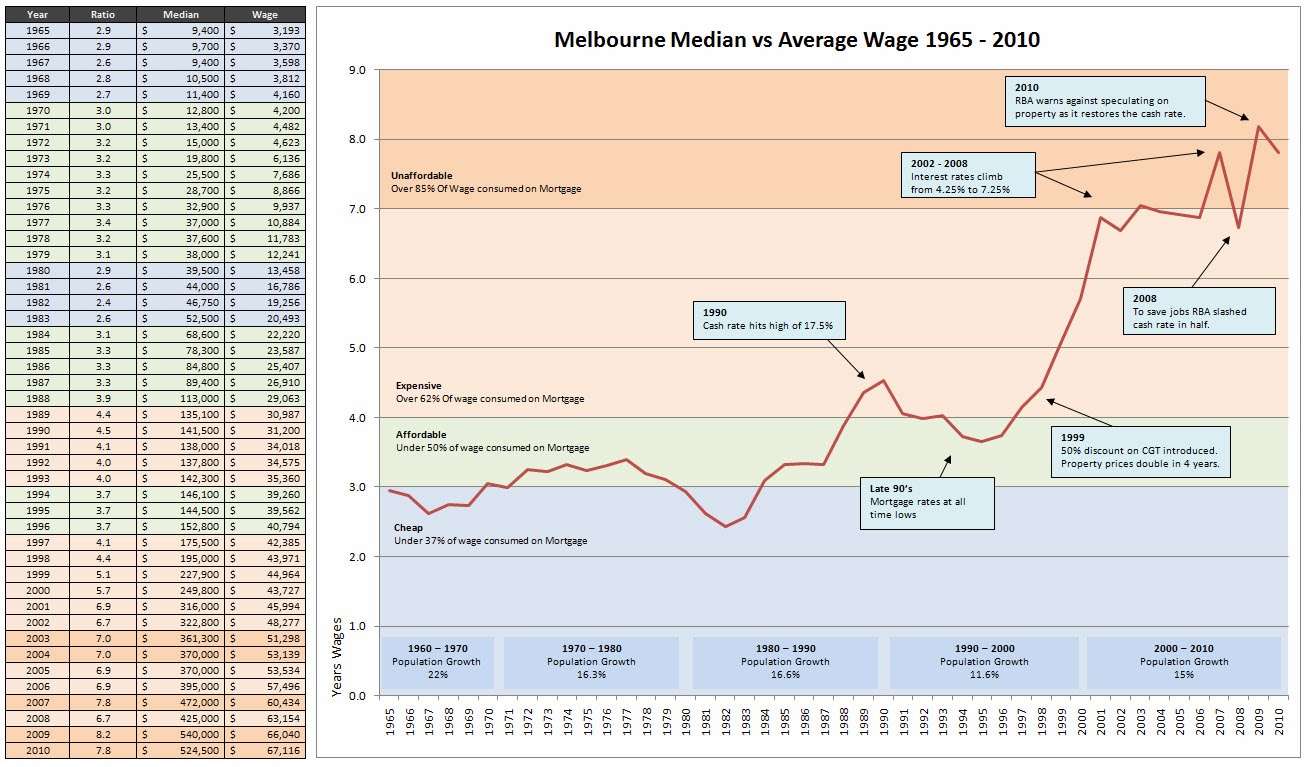
Melbourne Median vs Average Wage 1965 - 2010.
It must be remembered that house prices are determined by the demand and supply of credit, not the demand for and supply of housing.
房价不与国民收入,社会福利放在一起进行讨论,无异于光天化日里耍流氓。
AlphaGo is an intriguing movie, full of striking imagery.
Proud of witnessing DeepMind and Google are making history …
“The A.I. Revolution Will Not Be Supervised.”
- Yann LeCun
There is a simple way, using RESTful client to create Index and Mappings in ElasticSearch, for example, with ElasticSearch Head plugin.
Create Index in ElasticSearch with Settings JSON file. URL: http://localhost:9200/orders/, Method: PUT
1 | { |
Create Mappings in ElasticSearch with Mappings JSON file. URL: http://localhost:9200/orders/_mapping/order, Method: PUT
1 | { |
To add a new fields to ElasticSearch, while dynamic mapping is off:
1 | { |
Run with additional fields JSON file, with URL: http://localhost:9200/orders/_mapping/order, Method: PUT
1 | { |
An ElasticSearch query example, with URL: http://localhost:9200/orders/_search, Method: POST
1 | { |
An example query with date/time type in a range:
1 | { |
There are some secret of AWS credentials, i.e., its Access Key ID and Secret Access Key, which let you connect AWS services withouth authentication.
In a quintessential project environment, you have dev, test, prod environment setup in AWS. Your local AWS_PROFILE is something like this so you can switch to different targeting end services while run your application on localhost:
1 | 𝜆 cat ~/.aws/credentials |
When test Jest client in Test environment, a AWS ElasticSearch client library, error thrown:
1 | 2018-02-27 15:18:19 INFO org.paradise.search.routes.ElasticSearchRoute - Body: io.searchbox.core.Index@4804b850[uri=orders/order/4SMK1UmbtqIAAAFhmYAFt9V7,method=PUT] message: searchIndexRoute - updating search index |
It turns out that WRONG Dev AWS_PROFILE applied in Test environment.
Replacing “aws_access_key_id” and “aws_secret_access_key” from the default profile with “aws_access_key_id” and “aws_secret_access_key” from test profile:
1 | 𝜆 cat ~/.aws/credentials |
Rerun the test and in log:
1 | 2018-02-27 15:23:54 INFO org.paradise.search.routes.ElasticSearchRoute - Body: io.searchbox.core.Index@62b18125[uri=orders/order/RVwK1UIBXmoAAAFhdJkFo9WA,method=PUT] message: searchIndexRoute - updating search index |
There are several ways to access Amazon AWS ElasticSearch and Kibana services, which are HTTP based, without inject into HTTP request headers with authentication key …
Install a proxy application - AWS ES/Kibana Proxy. Download it from https://www.npmjs.com/package/aws-es-kibana and install:
1 | $ npm install -g aws-es-kibana |
Run AWS ES/Kibana Proxy then connect to ElasticSearch and Kibana services on AWS:
1 | $ cat ~/.aws/config |
With Fish Shell:
1 | 𝜆 env AWS_PROFILE=ap-test aws-es-kibana search-paradise-esv5-test-01-esd-blah23dlaoed81nz890adle4.ap-southeast-2.es.amazonaws.com |
Set up SSH Tunnel for AWS ElasticSearch https://search-paradise-esv5-test-01-esd-blah23dlaoed81nz890adle4.ap-southeast-2.es.amazonaws.com from 443 port to localhost 9200:
1 | 𝜆 ssh -L 9200:search-paradise-esv5-test-01-esd-blah23dlaoed81nz890adle4.ap-southeast-2.es.amazonaws.com:443 -l ec2-user aws-jump-box |
Then access AWS ElasticSearch at: https://localhost:9200, AWS Kibana at: https://localhost:9200/_plugin/kibana
With plugin ElasticSearch Head, to query ElasticSearch, using URL and index “orders-search-box” e.g. https://localhost:9200/orders-search-test/, and context path “_search”
And good things come in two (好事成双)。
想当初买耳机时对市场做过的一番调研,对欧洲,日本大厂的产品也略知一二。当同事介绍 Bluedio (蓝弦),一家从没听说过的中国广州公司生产的耳机时,以为仅是一家 Made In China,价廉低质的山寨产品。但被告知 Bluedio 耳机在亚马逊销量排行第二后,着实地大吃一斤。
Si vous voyez un entrepreneur chinois sauter par la fenêtre, suivez-le, il y a srement de bonnes affaires à faire (If you see a Chinese entrepreneur jumping out the window, follow him, there is certainly of good bargains to be done).
亚马逊的用户多非呆瓜。当吃瓜群众争先恐后地 jumping out of window 时,you have to follow. There is certainly of good bargains to be done.
货比三家后在 Aliexpress 下了单。
Bluedio Ai 从澳洲本土发货。三天后收到。
我对运动耳机要求不高。轻便,舒适,锻炼时不要总分心它会掉下来。用过从 $5 的 cheapy 到高端 Apple EarPods,没一个令人满意。
经过一段时间的使用,已感觉 Ai 是我所求。跑步时戴上感觉不到存在。耳机,人与自然达成和谐,已融为一体了。
从国内经阿里特快(免费的),Bluedio F2 两周后也到了。”F” 代表 Faith (忠诚)。F2 在外观设计上也忠诚地拷贝了著名的 Bose QC-35。One on one 比较,F2 在重量上比 QC-35 上了一个级别。但全金属 frame,让强烈厌恶塑料感的用户体会到厂家的温暖。耳机各个方面做工优异,用料实足,多处细节表现出匠人用心。
试听了 a wild range 不同风格的音乐作品后,you could feel the rich bass, warmer tone, not overpowering highs, and very detailed clarity from F2. 音质与高端耳机足有一拼。
Active Noise Cancelation (ANC) 不如 QC-35. 外界的蜂鸣声在经过 noise cancelation 后统统淹没在一片白噪声中。
谈到音质,F2 还不是 Bluedio 的最强产品。Bluedio 有一款 Victory 系列的 headphones,with 12 drivers,相当于有十二个 speakers 的一对音箱 built-in 小小的 headphones 里,提供了 studio level 的音质享受。对高品质继续 following.
Final thought.
$52 for a 高性价比的 wireless wheadphone plus ANC like this, nothing could go wrong. 惊喜之余,你会觉得对这个耳机每一分钱的投资都是物超所值。
Top range products on same market now like Sennheiser PXC 550 (Best Audio Quality), Sony WH1000XM2 (Most Elegant Design) and Bose QC 35 II (People’s Choice), cost 10x what you pay for Bluedio。Bluedio 在有些方面与顶级产品还有距离,but spend $500 for one 有额外享受的 headphone 是否真有所值? Furthermore, think about if you wear them cross the road, and you are run over by car, that will seriously damage these expensive headphones.
长城永不倒,国货当自强。
Bought one OnePlus 5T Lava Red (熔岩红) special edition from OnePlus China website - http://rush.oneplus.cn/ in December 2017, when this edition is first available and exclusively sale in mainland China, which Red Colour is very popular in China that means bringing you a good fortune.
Dual SIMs support. Having two mobile network carriers ALL in active mode.
by AnTuTu Benchmark
by Geekbench
by SpeedTest - ADSL2 connection
Support Dual Cameras and Portrait mode
OnePlus One,OnePlus 2,OnePlus 3,OnePlus 5, along with OnePlus 5T,一部完全一加手机的编年史,更显用户对高质量,高性价比的一加产品的喜爱与忠诚。
What OnePlus stands for is a no-gimmicks smartphone manufacturer build around a community.
For a good example, OnePlus 5T, a phone is full of all the right ideas - hardware design, software responsiveness, and overall usability.
打动用户的好产品自己会热销,不在乎卖到哪里。一加所做的一切,不过是努力把该做的做得更好。
长城永不倒,国货当自强。
Never Settle.